در مقالات قبل با مفهوم کلی یادگیری ماشین و دو شاخه ی رگرسیون و خوشه بندی در یادگیری ماشین آشنا شدید. در این مقاله به شاخه ی دیگری از یادگیری ماشین به اسم طبقه بندی میپردازیم

Classification
طبقه بندی به شاخه ای از هوش مصنوعی اطلاق میگردد که زیر دسته ی الگوریتم های نظارت شده هستند و دارای ورودی ها و برچسب(لیبل) های مشخصی هست . در این گونه سیستم ها الگوریتم تلاش میکند تا بین داده ها و برچسب های آنها روابطی برای طبقه بندی داده و پیش بینی کلاس مناسب انتخاب کند.
این دسته الگوریتم ها همانند رگرسیون زیر دسته ی الگوریتم های نظارت شده هستند طبقه بندی داده ها را به چند دسته ی غیر پیوسته تقسیم میکنند. بسته به نوع نیاز و داده الگوریتم های طبقه بندی به دو شاخه ی اصلی طبقه بندی باینری و طبقه بندی چندکلاسه تقسیم میشوند.
طبقه بندی باینری
زمانی که داده های ورودی صرفا به دو دسته تقسیم میشوند.
طبقه بندی چندکلاسی
زمانی که داده های ورودی به بیش از دو دسته تقسیم میشوند.
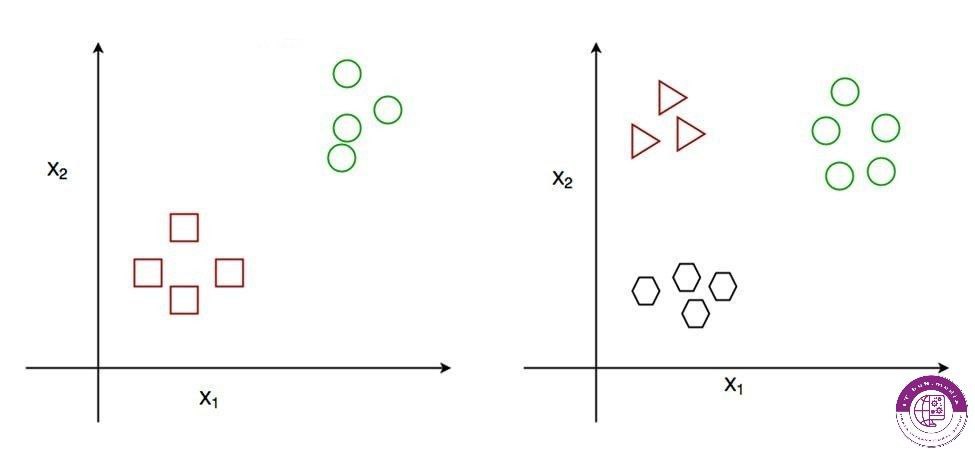
الگوریتم های طبقه بندی و نحوه ی عملکرد آنها
الگوریتم های طبقه بندی متعدد هستند و هر کدام برای مسائل خاصی طراحی شده اند.
معروف ترین الگوریتم های طبقه بندی عبارتند از:
KNN
Decision Tree
Logistic Regression
Support Vector Machine
KNN
KNN یا به فارسی “کی عدد نزدیک ترین همسایه” یکی از پرکاربردترین الگوریتم های طبقه بندی هست که داده های ورودی جدید رو براساس شباهت با کی همسایه ی نزدیک در یک گروه قرار میدهد.
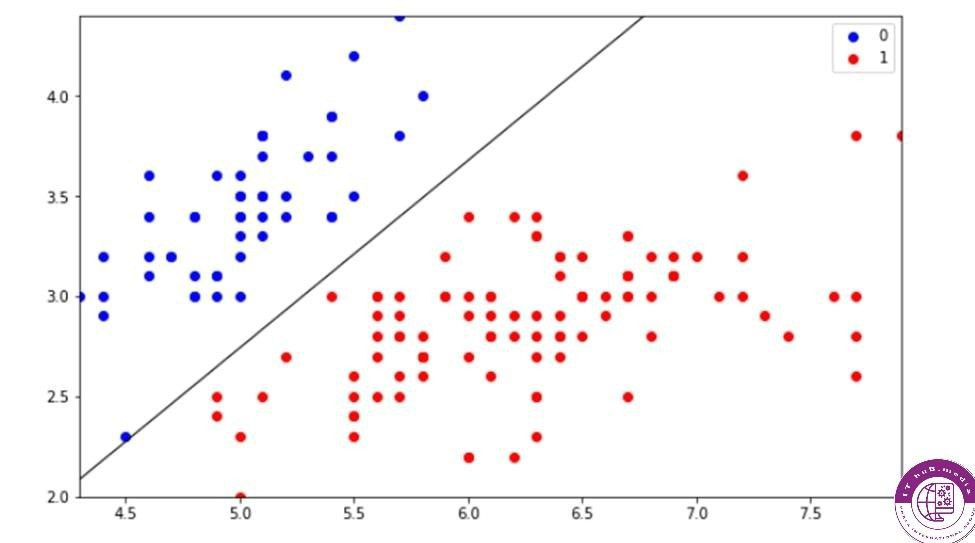
کی پارامتری قابل تنظیم هست و میتوان با زیاد یا کم کردن عدد کی به جواب های مختلفی دست پیدا کرد برای درک بهتر به عکس زیر توجه کنید
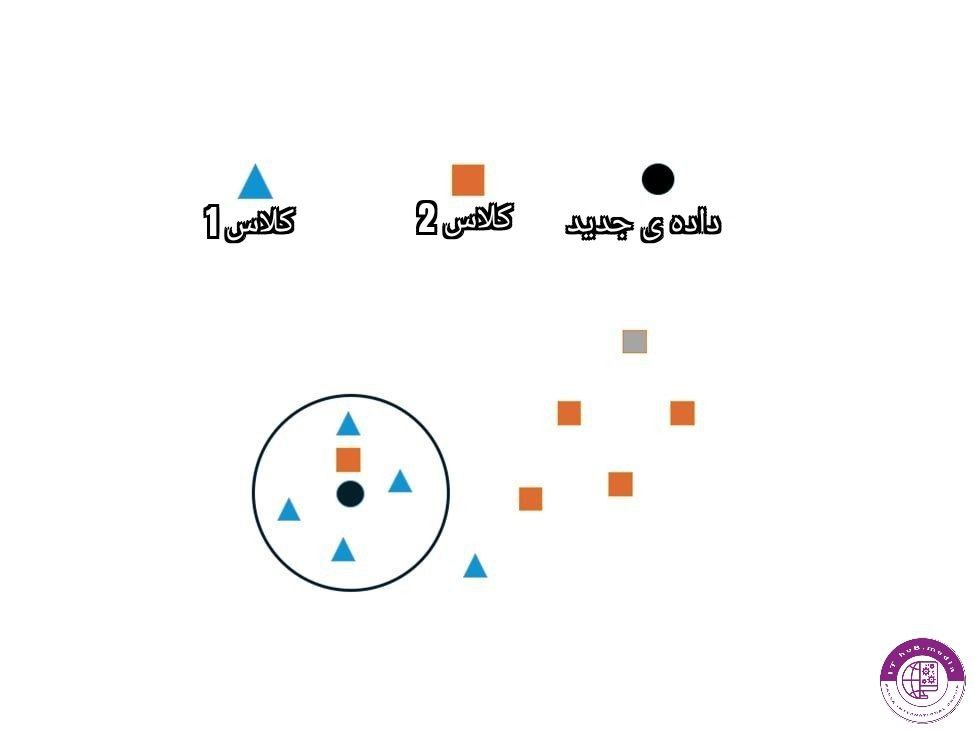
در اینجا متوجه اهمیت پیداکردن عدد درست برای کی میشوید، زیرا با وجود نزدیک بودن داده ای از گروه دو به داده ی جدید،در فاصله ی فضایی بزرگتر تعداد داده های گروه یک بیشتر هستند.
فاصله و نزدیکی و دور بودن داده ها را میتوان با فرمول های متعددی نظیر فاصله ی اقلیدسی حساب کرد پیدا کردن تنظیمات مناسب برای کی،به حدی که مدل بسیار ساده نشود یا از طرفی دیگر اورفیت نکند از بخش های اصلی بهبود مدل در این الگوریتم هست.
نقاط ضعف و قوت KNN
قوت:
1-الگوریتمی ساده و موثر برای برنامه نویسان تازه کار
2-سرعت و دقت بالا در داده هایی با تعداد داده ی کم
3-روش های متعدد برای پیدا کردن فاصله ی بین دو داده
4-قابل استفاده برای Regression و Classification
ضعف:
1-کندی در الگوریتم و ضعف در کاهش دقت تشخیص گروه داده های جدید با افزایش تعداد داده ها
2-عدم تعادل در گروه های داده منجر به کاهش دقت الگوریتم میشود 3-پیدا کردن مقدار مناسب کی برای داده ی جدید
Decision Tree
درخت تصمیم گیری شاخه ی دیگه ی از طبقه بندی هست که با پرسیدن سوال هایی از داده های ورودی به روش سلسله مراتبی تلاش میکند تا بین ترتیب داده های ورودی و خروجی مد نظر رابطه ای قابل قبول ایجاد کند.
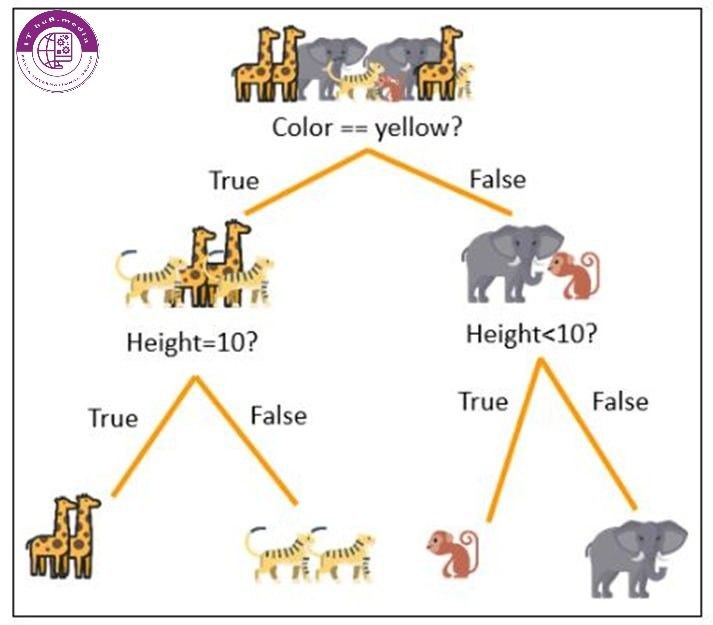
تصویر بالا با دو داده ی ورودی رنگ و قد و ترتیب مناسب تمامی داده ها را به گروه های جدا تقسیم کرد.
درواقع منظور از سلسله مراتبی ترتیب پرسیدن داده های ورودی در عنوان سوال و طبقه بندی کردن آنها به بهترین روش است. برای بررسی دقت این عمل از فرمول های ریاضیاتی استفاده میکنم که در بین آنان میتوان به مبحث و هایپرپارامتر انتروپی اشاره کرد.
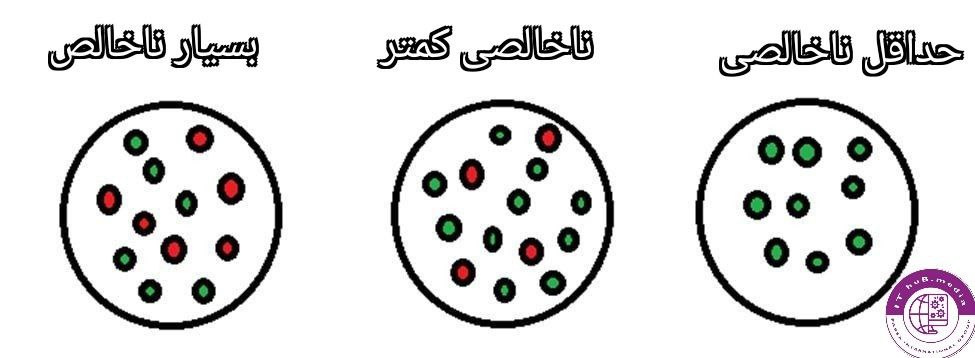
انتروپی به نظم یک سامانه ی داده ای بعد از هر طبقه بندی اشاره میکند و هرچقدر انتروپی یک داده کمتر باشد خلوص آن بیشتر و به همین منوال دقت الگوریتم بالاتر میرود.
انتروپی در پایتون یک هایپرپارامتر قابل تنظیم در کرایتریون درخت تصمیم هست و گزینه ی دیگر جینی هست.
نقاط ضعف و قوت درخت تصمیم گیری
قوت:
1-نیازمند وقت و تلاش کم در پروسه ی آماده سازی داده و مدل
2-عدم نیاز به توزیع استاندارد یا نرمالایز کردن داده
3-سادگی مفهوم الگوریتم
ضعف:
1-حساسیت به تغییرات
2-امکان پیشرفته و سخت شدن ریاضیات لازم برای محاسبات
Logistic Regression
در مقاله ی رگرسیون ها یاد گرفتیم که رگرسیون ها اغلب برای حساب کردن مقادیر پیوسته از ورودی پیوسته استفاده میشود.
اما لاجستیک رگرسیون برای طبقه بندی داده ها به صورت باینری یا چند دسته استفاده میشود.رگرسیون لاجستیک خطی همانند رگرسیون خطی بر اساس فرمول زیر عمل میکند:
C0 + X1C1+CX2C2+……+CNXN=Y
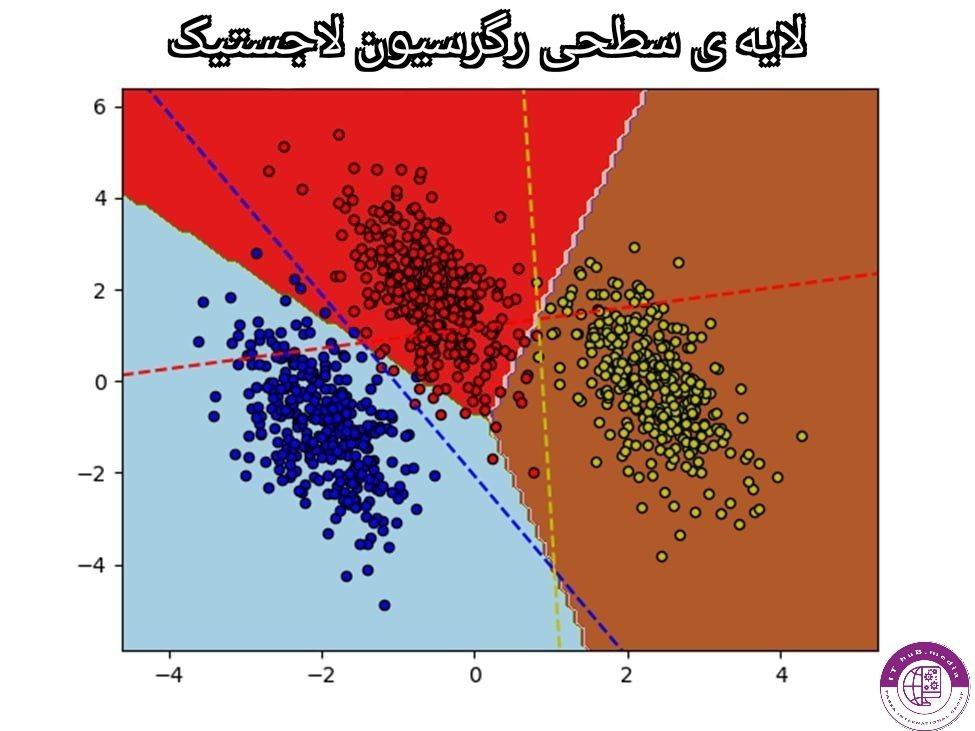
نقاط ضعف و قوت Logistic Regression
قوت:
1-سریع تر و راحت تر برای ساخت مدل و اجرا کردن
2-قدرت بیشتر در برابر اورفیت شدن
3-توانایی در تقسیم و طبقه بندی داده ها به دسته های متعدد
ضعف
1-خطی گرفتن نسبت بین داده های مستقل و وابسته
2-ضعف توانایی در استخراج روابط پیچیده
کاربرد های طبقه بندی
تجزیه و تحلیل احساسات:
مدلهای طبقهبندی میتوانند برای تجزیه و تحلیل و طبقهبندی دادههای متنی مانند پستهای شبکه ها اجتماعی، نقد و بررسی مشتری و بازخورد با استفاده از کلاسهای مثبت، منفی و خنثی استفاده شوند. این کار به شرکتها در درک نظرات مشتریان خود و تصمیمگیریهای مناسب کمک میکند.
تشخیص تقلب:
مدل های طبقهبندی میتوانند برای تشخیص تراکنشها و فعالیتهای تقلبی در مؤسسات مالی نظیر بانک ها استفاده شوند. با تجزیه و تحلیل دادههای تاریخی و شناسایی الگوها، این مدلها میتوانند تراکنشهایی را که تقلبی هستند، شناسایی کرده و مقامات مربوطه را مطلع کنند
تشخیص پزشکی:
مدل های طبقه بندی میتوانند در مسیر تشخیص بیماری های مختلف بر اساس عواملی مانند سابقه پزشکی بیمار،علائم و نتایج آزمایش مورد استفاده موثر قرار بگیرند. این امر میتواند به پزشکان برای تشخیص بیماری ها با دقت بالاتر و مراقبت های پزشکی بهتر کمک کند
تشخیص تصویر:
مدلهای طبقهبندی میتوانند برای تشخیص و طبقهبندی تصاویر به دستههای مختلف مانند حیوانات، اشیا و افراد استفاده شوند. این کار در حوزههایی مانند رانندگی خودکار، مراقبت امنیتی و تشخیص محصولات کاربرد دارد