در مقاله ی قبل درباره ی یادگیری ماشین و استفاده های آن در زندگی روزمره صحبت کردیم. یکی از استفاده های هوش مصنوعی و یادگیری ماشین در زمینه ی تشخیص ناهنجاری ها و کلاهبرداری به کمک الگوریتم خوشه بندی DBSCAN در زمینه های مختلف نظیر بانکداری میباشد.
اما چگونه؟
برای درک بهتر این مبحث لازم است اول با مبحث دسته بندی در هوش مصنوعی بیشتر آشنا شویم.
دسته بندی(Clustering)
الگوریتم های معروف یادگیری ماشین به دو دسته ی یادگیری ماشین با نظارت و بدون نظارت طبقه بندی میشوند.
در الگوریتم های با نظارت نیازمند آن هستیم که داده ها قبل از پردازش برچسب گذاری شوند تا برنامه توانایی محاسبه ی خروجی داشته باشد. این الگوریتم به سه دسته ی رگرسیون،طبقه بندی باینری و طبقه بندی چندکلاسی تقسیم میشوند.
اما الگوریتم های بدون نظارت نیاز به همچنین برچسب گذاری نداشته و تنها با یافتن الگوهایی مشخص در داده ها آنها رو گروه بندی میکنند.
کلاسترینگ یا دسته بندی از شاخه الگوریتم های بدون نظارتی هست که دقیقا توانایی پردازش چنین داده هایی را دارد.
Clustering خود نیز الگوریتم های متعددی دارد که هریک کارایی های ویژه دارند. این مقاله میخواهیم درباره ی الگوریتمی از کلاسترینگ به نام دی بی اسکن صحبت بکنیم
خوشه بندی با الگوریتم های کلاسترینگ
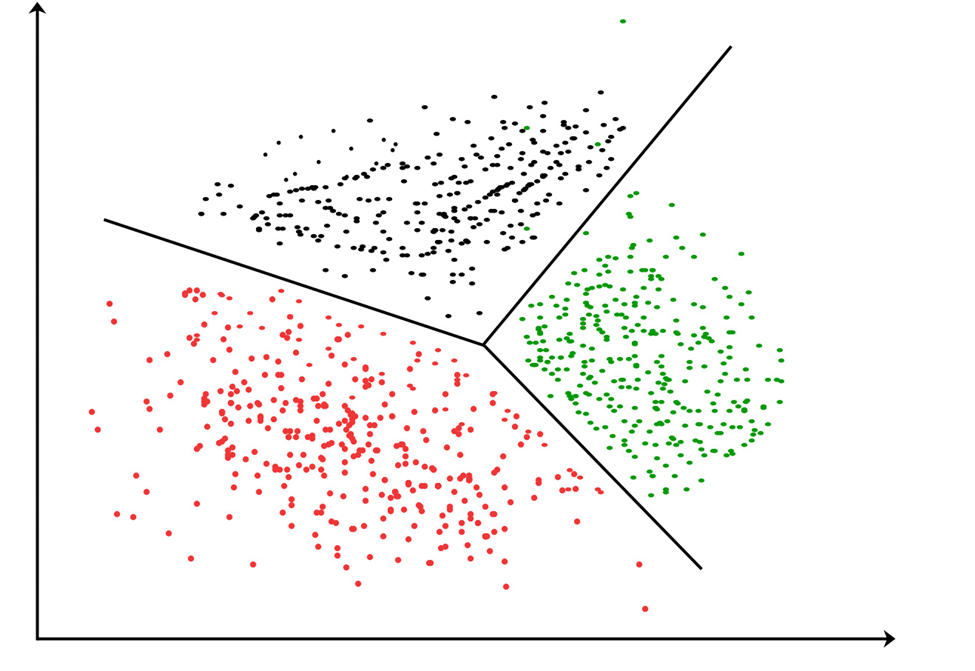
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN(دی بی اسکن) یکی از الگوریتم های دسته بندی میباشد که برای تشخیص ناهنجاری ها اختصاص یافته است. این الگوریتم نسبت به الگوریتم های دیگر دسته بندی توانایی مقابله با داده های نویز یا به اصطلاح هنجار را بهتر دارد. به این دلیل که برخلاف دیگر الگوریتم ها،DBSCAN تمامی داده ها را تحت هر شرایطی در یک گروه قرار نمیدهد. بلکه داده های نویز را از داده های گروه بندی شده جدا قرار میدهد.
اگر بخواهیم مثالی برای درک بهتر بزنیم میتوانیم از مرد پولداری که در محله ای فقیر نشین زندگی میکند استفاده کنیم.
صرفا با زندگی کردن این شخص در یک محله ی فقیرنشین سطح زندگی این محله بهتر نشده و هنوز محله ای فقیرنشین است. الگوریتم DBSCAN در اینگونه شرایط ها این شخص را به عنوان داده ی نویز یا ناهنجاری تلقی میکند و آن را کنار میگذارد که باعث افزایش دقت گروه بندی و دیگر اندازه گیری ها میشود.
DBSCAN یکی از الگوریتم های دسته بندی میباشد که برای تشخیص ناهنجاری ها اختصاص یافته و نسبت به الگوریتم های دیگر دسته بندی توانایی مقابله با داده های نویز یا به اصطلاح هنجار را بهتر دارد.
به این دلیل که برخلاف دیگر الگوریتم ها،DBSCAN تمامی داده ها را تحت هر شرایطی در یک گروه قرار نمیدهد و داده های نویز را از داده های گروه بندی شده جدا قرار میدهد
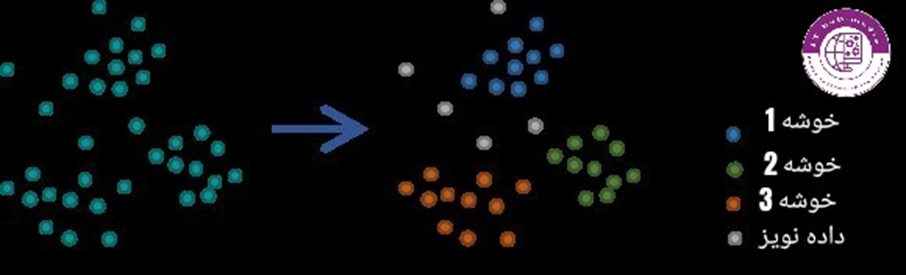
نحوه عمل DBSAN
ترجمه ی روان DBSCAN،خوشه بندی مبتنی بر چگالی فضایی برنامه ها با نویز میباشد. همانطور که اسم توضیح میدهد،الگوریتم در الگو به دنبال نقاط پرچگال میگردد که تعداد داده در آن بخش از فضا تعداد قابل قبولی دارد(این بخش میتوان تنظیم شود برای همین تعداد یا چگالی داده ای خاصی نمیتوان نام برد)
برای درک نحوه ی عمل دی بی اسکن باید با مفاهیم زیر آشنایی بیشتر پیدا کرد
Core point
Border Point
Noise Point
Neighborhood
Minimum Points
Epsilon
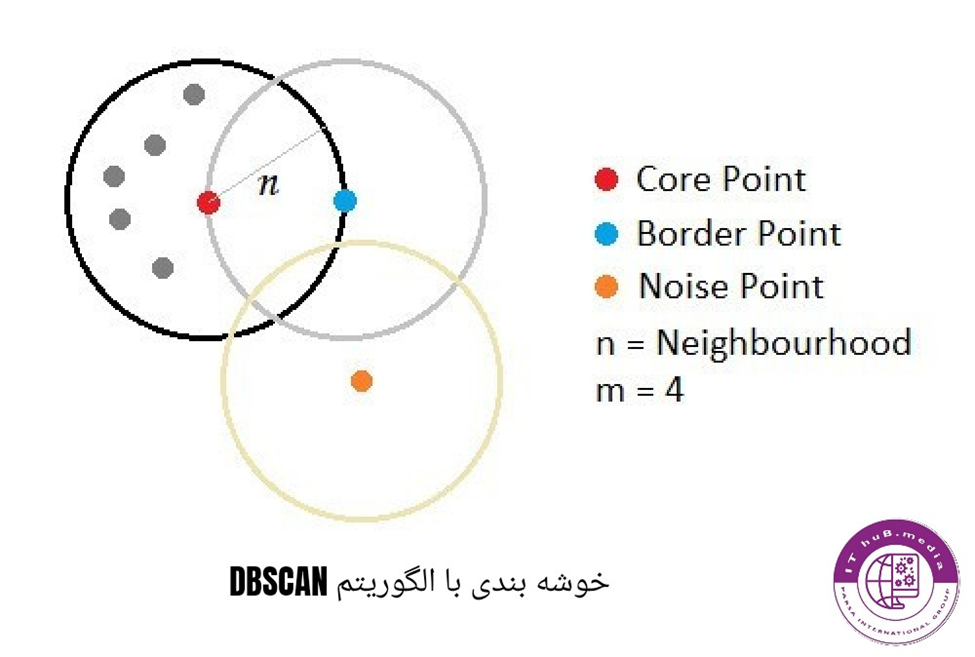
نقاط مرکزی یا Core Point ها مراکز خوشه ی ما هستند که از یک تا هر تعدادی که بخواهیم میتوان آنها را تنظیم کرد
اپسیلون به شعاع دایره ی خوشه گفته میشود که حول نقطه ی مرکزی هست و هر نقطه ای در این شعاع همسایه ی نقطه ی مرکزی شناخته شده و مجموع تمام این نقاط یک همسایگی تشکیل میدهند
نقاط مرزی یا Border Point ها انتهای هر خوشه هستند که اگر داده ای از آن سمت خارج شود جزو آن خوشه حساب نمیشود
نقاط ناهنجار یا نویز پوینت ها نقاطی هستند که در هیچ خوشه ای قرار ندارند
یک خوشه یا گروه زمانی تبدیل به گروه میشود که در شعاع نقطه ی مرکزی یافته شده توسط الگوریتم تعداد کافی نقطه باشد. به این Minimum Point یا حداقل تعداد نقطه میگویند. در حالی که الگوریتم های خوشه بندی دیگر برای قرار دادن نقاط نویز در داده حدود آن را تغییر میدهند، الگوریتم دی بی اسکن این کار را انجام نمیدهد. این امرDBSCAN را تبدیل به الگوریتمی بسیار ایده آل برای تشخیص ناهنجاری ها تبدیل میکند
ویدئوی آموزشی این مبحث و تعامل با DBSCAN در پایتون را میتوانید از آپارات ما مشاهده کنید