یادگیری ماشین چیست؟

یادگیری ماشین شاخه ای از هوش مصنوعی میباشد که به سیستم این اجازه را میدهد که به صورت خودکار و بدون دخالت برنامه نویس از داده های ورودی یادگیری و بهبود داشته باشد. چنین الگوریتم هایی از داده های ورودی و درصورت وجود برچسب های آنها شروع به یادگیری میکنند و تلاش میکند تا بدون دستورهای مشخصی، بین آنها روابطی یافته تا بتواند پیش بینی خود را هرچه بیشتر به واقعیت نزدیک بکند بدون آنکه برنامه نویس نیازی به دخالت در این پروسه داشته باشد.
یادگیری ماشین در دهه ی 1980 میلادی و با پیدایش الگوریتم هایی نظیر شبکه های عصبی و درخت تصمیم گیری به بلوغ خود رسیدند. از آن زمان یادگیری ماشین به عنوان ابزاری برای حل مشکلات نوین انسان ها تلقی شد.
الگوریتم های یادگیری ماشین
در یادگیری ماشین الگوریتم ها اغلب براساس نحوه ی انتخاب الگوریتم یادگیری و نحوه ی کار با داده به سه بخش تقسیم میشوند:
الگوریتم های نظارت شده(Supervised Learning)
بدون نظارت(Unsupervised Learning)
یادگیری تقویتی(Reinforcement Learning)
که دو شاخه ی نظارت شده و بدون نظارت نیز به شاخه های مختلف تقسیم میشوند
یادگیری نظارت شده
در این شاخه از یادگیری ماشین داده ها برچسب گذاری شده اند،به معنای آنکه هم داده های ورودی و داده های خروجی هر دو از قبل مشخص هستند و هدف الگوریتم بر این اساس است که تلاش کند تا رابطه ای بین ورودی و خروجی بیابد
دوشاخه ی اصلی یادگیری نظارت شده رگرسیون و طبقه بندی کلاسی میباشد
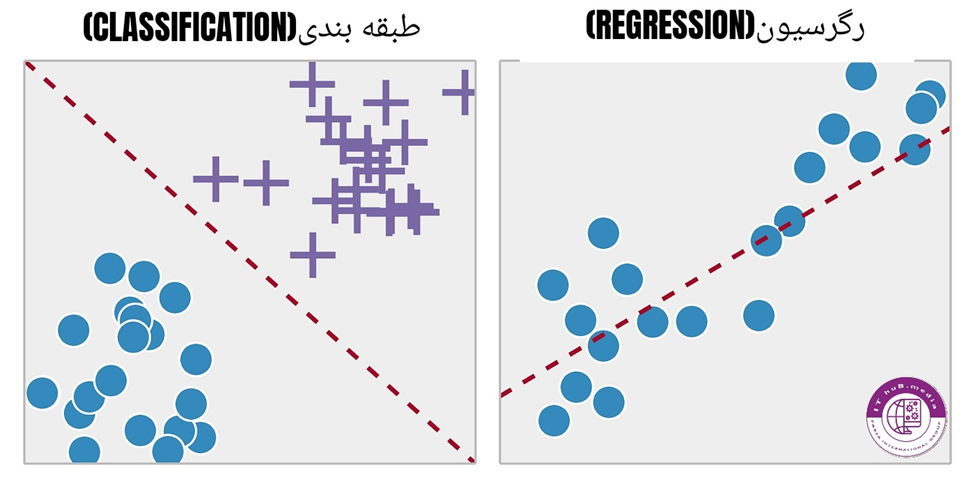
- رگرسیون(Regression):
برای پیش بینی مقادیر پیوسته استفاده میشود،از کاربردهای آن میتوان در پیش بینی قیمت مسکن با کمک داده های ورودی اشاره کرد.
- طبقه بندی(Classification):
برای پیش بینی مقادیر غیر پیوسته استفاده میشود،به طور مثال پیش بینی حالت چهره بین سه خروجی خوشحال،ناراحت و بدون احساس.
طبقه بندی به دوشاخه ی باینری و چندکلاسه تقسیم میشود.
- طبقه بندی باینری(Binary Classification):
برای تقسیم داده ها به دو دسته ی غیر پیوسته،از کاربرد های آن میتوان به تشخیص وجود یا عدم وجود غدد سرطانی در زمینه ی پزشکی اشاره کرد.
- طبقه بندی چندکلاسی (Multi-Class Classification):
برای تقسیم داده ها به بیش از دو دسته ی غیرپیوسته،به طور مثال طبقه بندی داده ای مربوط به اقلام پوشاک در 4 دسته ی کفش،شلوار،پیرهن و کلاه.
الگوریتم های با نظارت در یادگیری ماشین
یادگیری نظارت نشده
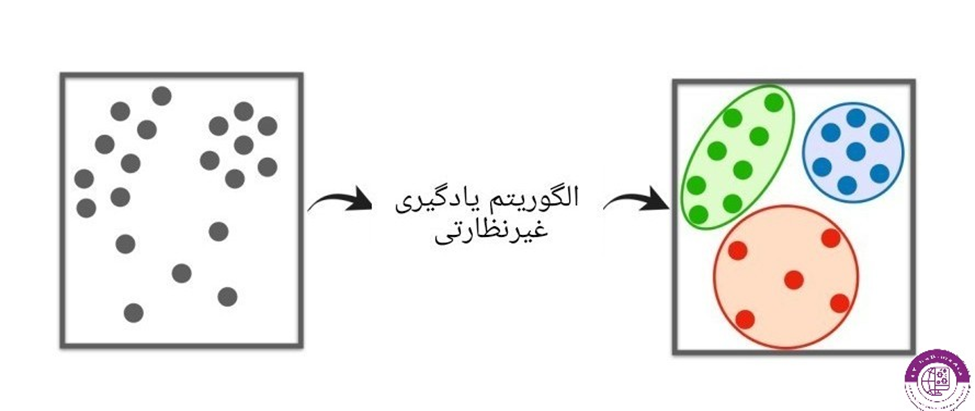
الگوریتم های یادگیری نظارت نشده زمانی استفاده میشوند که داده ها برچسب ندارند و خروجی آنها مشخص نیست
در این روش الگوریتم داده های بررسی میکند تا بتواند الگوهایی بین داده های بیابد.الگوهایی که بعدا بتوان از آنها برای گروه بندی داده ها استفاده شود
الگوریتم های نظارت نشده در خوشه بندی به کار میروند
(Clustering)خوشه بندی
برای تقسیم داده ها خوشه بندی آنها گروه های مختلف براساس شباهت میان داده ها،از کاربرهای این سیستم ها میتوان به گروه بندی مشتری های بانک ها و یا ارزیابی داده های مربوط به ورزشکاران و خوشه بندی آنها به گروه های مختلف اشاره کرد
(Reinforcement Learning)یادگیری تقویتی
الگوریتم های یادگیری تقویتی دارای اهدافی مشخص هستند که در محیطی باید به آن دستیابی پیدا بکنند
این گونه الگوریتم ها داده ای به صورت ورودی یا خروجی ندارند و از سیستم تشویق و تنبیه در آنها استفاده میشود،به این صورت که در محیط مشخص داده موانعی وجود داشته که در صورت برخورد به آن موانع یا انجام حرکتی اشتباه سیستم تنبیه شده و به آن نمره ی منفی داده میشود و در صورت رسیدن به هدف یا انجام دادن حرکتی درست به آن نمره ی مثبت به عنوان تشویق داده میشود و تا زمانی که سیستم به هدف نرسد یادگیری آن در محیط ادامه میابد.
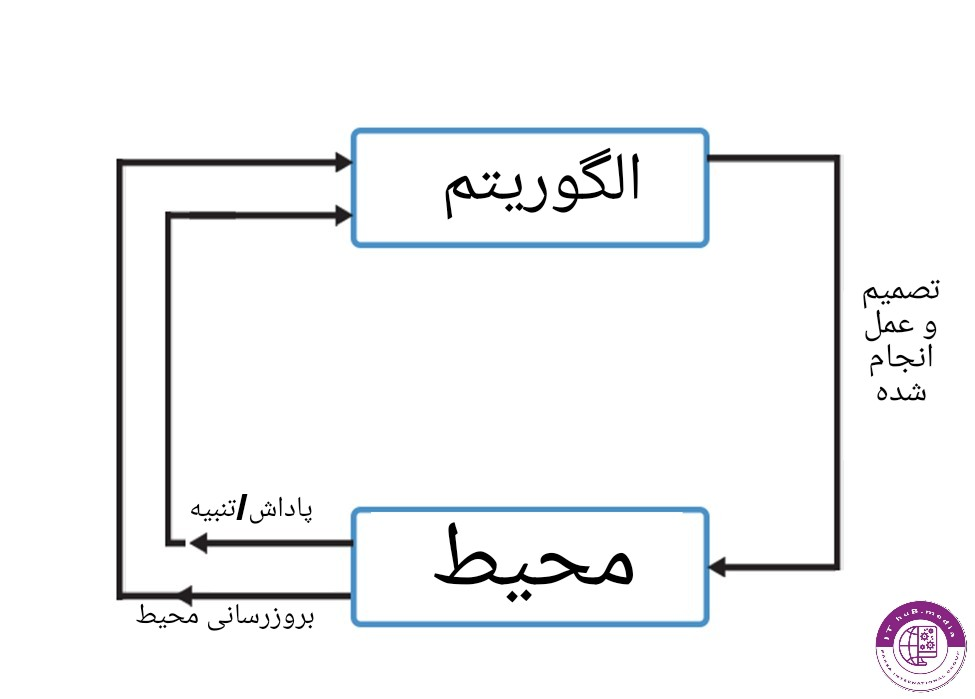
به تعامل الگوریتم با محیط؛تشویق و تنبیه شدن و یادگیری آن یادگیری تقویتی گفته میشود. از کاربردهای یادگیری تقویتی میتوان به تاکسی های خودران اشاره کرد.
Support Vector Machines(SVM)
ماشین های برداری قابل پشتیبانی یکی از الگوریتم های یادگیری ماشین در زمینه ی الگوریتم های نظارت شده میباشد که برای طبقه بندی یا رگرسیون داده استفاده میشود.
الگوریتم های اس وی ام بر اساس یک جداکنند یا سپرتور عمل میکنند که داده ها را از یکدیگر جدا میکنند.
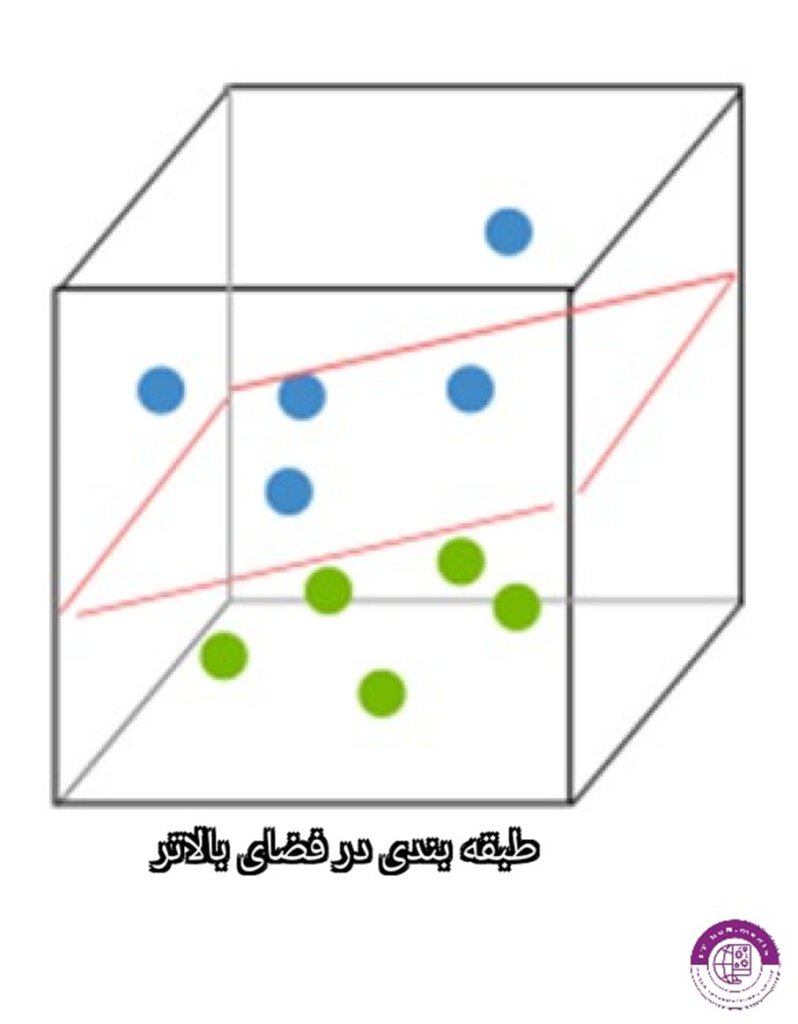
این سپرتور در فضای دو بعدی به صورت یک خط و در فضای سه بعدی به صورت صفحه است. هدف و نحوه ی کار اس وی ام جداسازی داده ها با سپرتور در فضایی در یک بعد بالاتر میباشد. که در مثال زیر بیشتر با این مفهوم آشنا میشوید
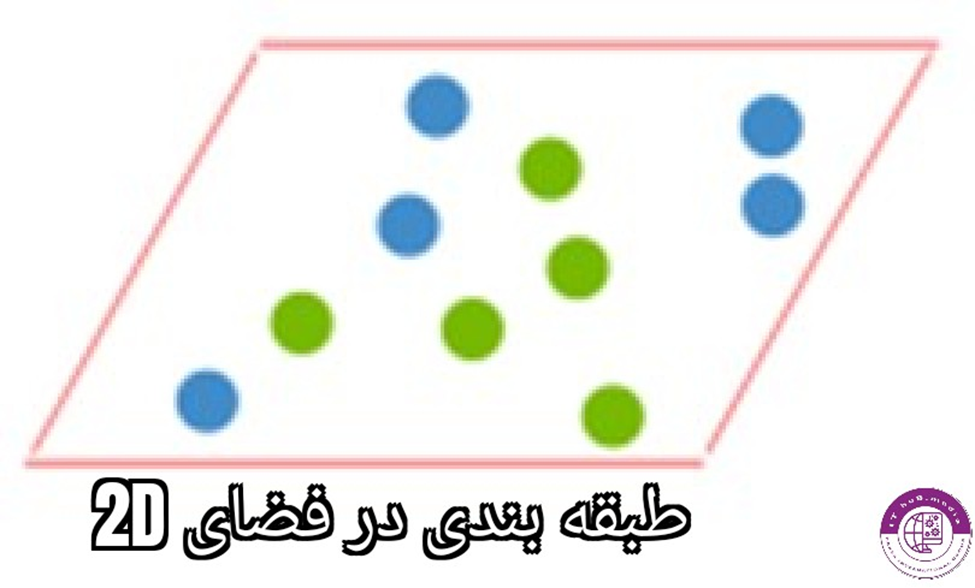
در تصویر بالا طبقه بندی داده ها را در دو بعدی مشاهده میکنید که به صورت یه خط مستقیم قابل طبقه بندی نیستند،اما اگر یک بعد به این مسئله اضافه بکنیم و از فضای سه بعدی به این داده نگاه بکنیم با همچین طبقه بندی تمیزی مواجه میشویم.
مفاهیم SVM
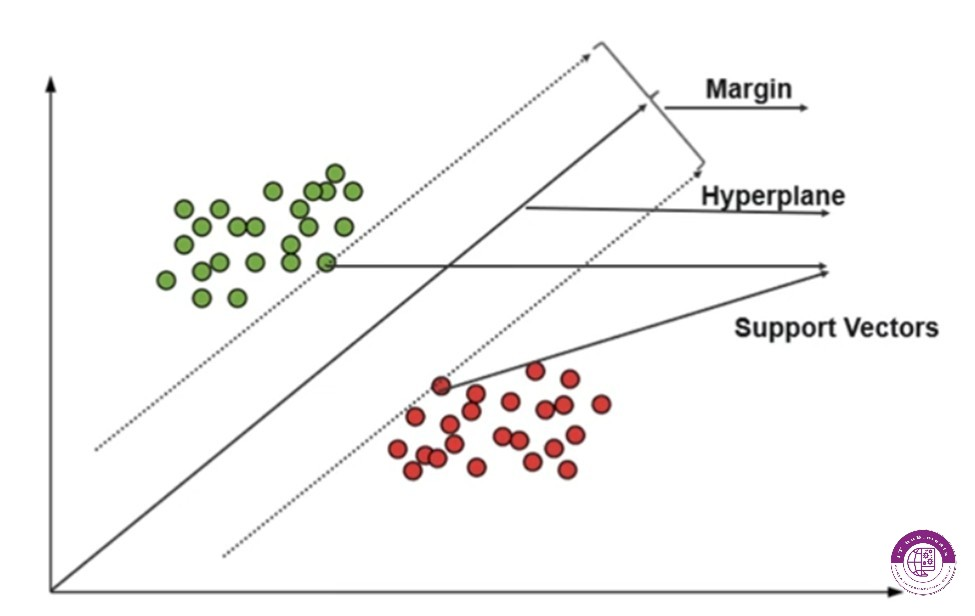
برای درک بهتر ماشین های برداری قابل پشتیبانی باید با سه مفهوم زیر آشنایی بهتری پیدا کنید
Support Vectors
Margin
Hyperplane
بردارهای قابل پشتیبانی به دو داده از هر گروه میگویند که نزدیک ترین فاصله را با یکدیگر دارند.به این صورت که با کشیدن خطی از این دو داده فضایی بین دو گروه ایجاد شود که در این فضا هیچ داده ای از دو گروه مشاهده نمیشود. به این فاصله مارجین میگویند،و به خطی که مارجین را به دو بخش کاملا مساوی تقسیم میکند هایپرپلین میگویند.
ماشین های برداری قابل پشتیبانی به دلیل توانایی قوی در طبقه بندی داده ها در طبقه بندی و رگرسیون استفاده شده و الگوریتم محبوبی در داده های نامرتب و داده های چالش برانگیز میباشد.
از کاربردهای ماشین های برداری قابل پشتیبانی میتوان به تشخیص عکس یا طبقه بندی پیغام ها اشاره کرد.
کتابخانه های معروف مرتبط با یادگیری ماشین
در برنامه نویسی در زمینه ی یادگیری ماشین کتابخانه های زیادی وجود دارند که به کاربر دسترسی به ابزارهای مفید و متعددی میدهند
بعضی از این کتابخانه های عبارتند از
Numpy
Scipy
Scikit-Learn
Numpy
نامپای کتابخانه ای در پایتون هست که برای کار با آرایه های چندبعدی،ماتریس ها و محاسبات اعدادی در پایتون ساخته شده. از کتابخانه های مهم در زمینه ی هوش مصنوعی میباشد و زمینه ساز ساخت بسیاری دیگر از کتابخانه های محاسباتی پایتون و هوش مصنوعی مانند پانداس،متپلات لیب،سایکیت لرن و تنسورفلو میباشد.
Scipy
سای پای کتابخانه ای مختص به عملیات های محاسباتی و ریاضی در پایتون هست که به کاربر دسترسی به ابزارهایی سطح بالا برای وظایف متعددی مانند تغییر داده و محاسبات میدهد
از کاربردهای سای پای میتوان به تغییر و دستکاری داده،محاسبات انتگرالی،فانکشن های بهبود دهنده،پردازش سیگنال و جبرخطی اشاره کرد
Scikit-Learn
از کتابخانه های معروف در زمینه ی یادگیری ماشین میتوان به سایکیت لرن اشاره کرد.
این کتابخانه اپن سورس بوده و از ابزارهای زیادی برای ساخت و بهبود الگوریتم های متعدد یادگیری ماشین بهره مند میباشد
تعامل با کتابخانه های یادگیری ماشین در بستر پایتون و ویدئوی محتوای فوق را میتوانید در آپارات ما مشاهده بکنید