یادگیری عمیق چیست
یادگیری عمیق (Deep Learning) یکی روش از روشهای یادگیری ماشین است که به صورت خودکار از دادههای ورودی یاد میگیرد و قابلیت تشخیص الگوهای پیچیدهتر و جزئیتر را داراست. در این روش، شبکههای عصبی عمیق برای یادگیری و تفسیر دادهها استفاده میشوند. این شبکهها از لایههای چندگانه تشکیل شدهاند که هر لایه به دادههای ورودی چهارچوبی جدید میدهد و با افزایش تعداد لایهها، قابلیت تشخیص الگوهای پیچیدهتر و عمیقتر افزایش مییابد. به دلیل شباهت ساختار شبکه های عصبی عمیق آن را به شبکه ی عصبی مغز انسان تشبیه میکنند. یادگیری عمیق در حوزههای مختلفی از جمله پردازش تصویر، پردازش گفتار و ترجمه ماشینی استفاده میشود. همچنین در زمینههایی مثل تشخیص چهره، تشخیص الگو و پردازش زبان طبیعی نتایج قابل قبولی داشته است. برای درک بهتر مفهوم یادگیری عمیق لازم است با مفهوم شبکه های عصبی و نحوه ی کار آنها آشنا شوید.

شبکه های عصبی
شبکههای عصبی، همچنین به عنوان شبکههای عصبی مصنوعی یا شبکههای عصبی شبیهسازی شده نیز شناخته میشوند، زیرمجموعه ای از یادگیری ماشین هستند و بخش اصلی الگوریتمهای یادگیری عمیق واقع میباشند. نام و ساختار آنها از ساختار شبکه های عصبی مغز انسان الهام گرفته شدند زیرا رفتاری شبیه سلولهای عصبی طبیعی را تقلید میکنند.
شبکه های عصبی از یک لایه ورودی که اطلاعات به آنها وارد میشوند،یک یا چندین لایه مخفی که اطلاعات را از لایه ی ورودی گرفته و پردازش بیشتر بر روی آنها انجام داده و یک لایه خروجی تشکیل شده اند. هر لایه از تعدادی نورون تشکیل شده اند که به لایه های بعدی وصل شده اند و دارای یک وزن و یک آستانه میباشد. اگر داده ی ورودی به نورون از آستانه ی تعریف شده بالاتر باشد آن نورون فعال شده و اطلاعات را به نورون بعدی ارسال میکند.
این شبکه ها برای تمرین کردن و بهبود دقت خود بر روی داده های ورودی بزرگ و حجیمی که در یادگیری ماشین کار با آنها سخت یا ناممکن است ساخته شده اند تا در گذر زمان و تمرین بتوانند به دقتی بالا برسند.
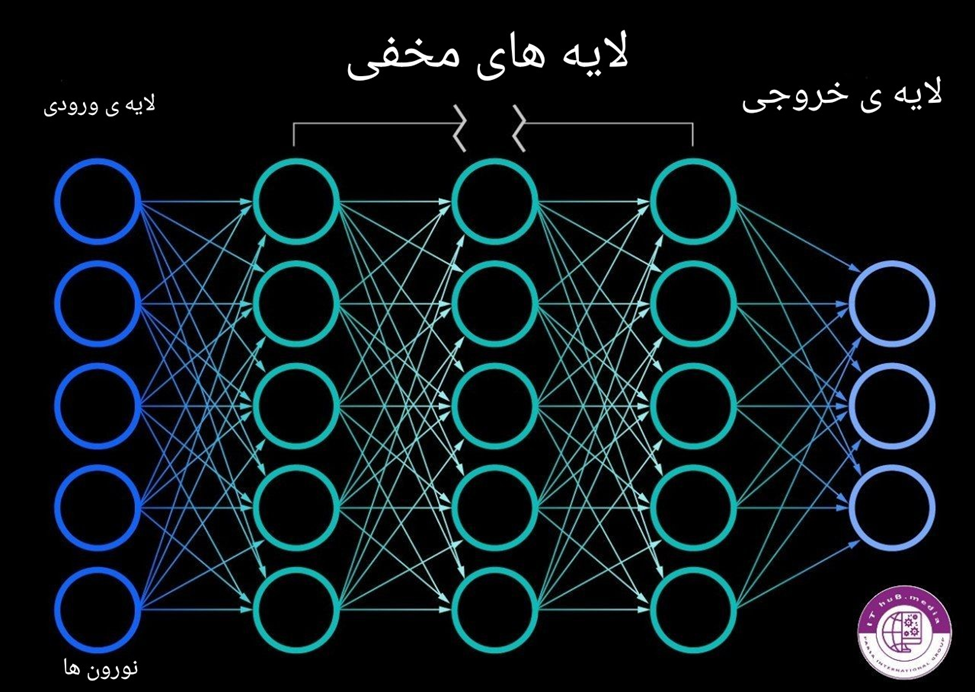
وزن ها،آستانه و انتقال داده در شبکه ی عصبی
اکنون برای درک بهتر ریاضیات پشت شبکه های عصبی،یک لایه را در نظر میگیریم که در آن هر نورون یک ورودی،وزن،آستانه و یک خروجی دارد. این مفاهیم به صورت ریاضیاتی به این شکل نوشته میشود:
Output= w1i1 + bias
که در آن متغییر آی ورودی ما،دبلیو وزن ما و بایاس همان آستانه ی ما میباشد.
که اگر در بیش از یک نورون بخواهیم این را بنویسیم به این صورت نوشته میشود:
WnIn + bias = W1I1 + W2I2 +……..+ WnIn + bias∑
Output=1 if ∑WnIn + bias >=0; 0 if ∑WnIn + bias <0
بیایید با مثال سینما رفتن این مفهوم را بهتر توضیح دهیم:
در سینما رفتن سه فاکتور شلوغ بودن،وضعیت آب و هوا و قیمت بلیط سینما برای شما مهم است
برای هرکدام به صورت باینری ارزش تعیین میکنیم.
آیا سینما شلوغ است؟(خیر=1 ، بلی=0)
آب و هوا مساعد است؟(بلی=1، خیر=0)
قیمت بلیط معقول است؟(بلی=1،خیر=0)
حال بعد از جستجو متوجه میشویم که قیمت بلیط ها معقول هستند،سینما شلوغ و آب و هوا مناسب است پس نوشته میشود:
I1=0
I2=1
I3=1
در اینجا خروجی موردعلاقه ی شما ارزش 1 میگیرد و خروجی که برای شما مساعد نیست خروجی 0 میگیرد.
حال وقت این است که به هرکدام از این ورودی ها یک وزن با درنظر گرفتن اهمیتشان بدهیم.
به شلوغی سینما وزن 2 میدهیم چون برای شما خیلی حائز اهمیت نیست.
به شرایط جوی وزن 5 میدهیم چون بسیار مهم است و شما نمیخواهید در هوای بارانی از خانه خارج شوید.
و درنهایت به قیمت بلیط وزن 4 میدهیم.
در انتها برای تمام کردن معادله به آن آستانه ی 4.5 میدهیم که در معادله 4.5- نوشته میشود.
WnIn + bias = W1I1+ W2I2+W3I3+bias= (0*2) + (1*5) + (1*4) – 4.5
Output=1 (4.5>=0)
پس در این سناریو شما به سینما میروید. اما شما میتوانید با تنظیم کردن وزن ها یا آستانه یا استفاده از ورودی های بیشتر میتوانید به نتیجه ای مختلف برسید.
تابع فعال سازی(Activation Function)
یک تابع فعالسازی، یک تابع ریاضی است که در شبکههای عصبی مصنوعی به کار میرود و با اعمال یک تحول غیرخطی بر روی جمع وزندار ورودی ها که با بایاس جمع شده تا بتواند مدل را از حالتی خطی به غیرخطی تبدیل بکند. این عمل اجازه میدهد تا شبکه الگوها و روابط پیچیدهتری را بین ورودی و خروجی یاد بگیرد. انواع مختلفی توابع فعالسازی وجود دارند که هرکدام ویژگی و عملکرد های خاصی دارند و برای حل برخی مسائل خاص به کار میروند.
در مثال قبل اگر بخواهیم تابع فعالسازی نیز به کار ببریم معادله به این صورت نوشته میشود:
Output= Activation Function (w1i1+w2i2+w3i3+bias)
تابع زیان (Loss Function)
تا کنون با مفاهیم زیادی از شبکه ی عصبی آشنا شدید،در انتها میخواهیم درباره ی لاس فانکشن یا تابع زیان صحبت بکنیم.
در مسائلی که مقادیر حقیقی داده را داریم و میخواهیم به کمک آنها شبکه ای طراحی بکنیم که بتواند بدون داشتن مقادیر جواب به جوابی دقیق برسد لاس به چشم میاید که در واقع تفاوت بین مقدار حقیقی داده و مقدار حدس زده شده توسط سیستم میباشد. لاس فانکشن ها به این دلیل ساخته شده اند که شبکه را درصورت اشتباه به سمت مقدار حقیقی برسانند. یکی از اهداف شبکه ی عصبی کم کردن مقدار زیان(لاس) و رساندن آن به حداقل میزان ممکن میباشد که یکی از روش های اندازه گیری میزان قدرت و دقت یک شبکه ی عصبی میباشد.
در ادامه با اسامی برخی از این تابع ها آشنا میشوید:
Mean Absolute Error (MAE) Loss
Mean Squared Error (MSE) Loss
Binary Cross-Entropy Loss
Categorical Cross-Entropy Loss
Huber Loss

تاریخچه ی یادگیری عمیق و شبکه های عصبی
تاریخچه ی یادگیری عمیق و شبکههای عصبی مصنوعی ریشه در دهه ۱۹۴۰ دارند. اولین شبکه عصبی مصنوعی در سال ۱۹۴۳ توسط وارن ماک کولوخ و والتر پیتز ساخته شد. این شبکه بر اساس این ایده بود بتوان سیستم های پیچیده را به وسیله ی واحد های محاسباتی ساده و مرتبط طراحی کرد.
در دهههای ۱۹۵۰ و ۱۹۶۰، پژوهشگرانی همچون دونالد هب، ماروین مینسکی و سیمور پاپرت پیشرفتهای قابل توجهی در تئوری شبکههای عصبی داشتند که پایههای توسعه مدلهای دیپ لرنینگ را فراهم کرد.
در دهه ۱۹۸۰، تکنیک بک پراپاگیشن به عنوان روشی محبوب برای آموزش شبکههای عصبی شناخته شد. اما محدودیتهای در قابلیت محاسباتی و دسترسی به دادهها باعث کاهش محبوبیت آنها شد.
بازگشت دوباره برنامه نویسان و استفاده از شبکههای عصبی مصنوعی و دیپ لرنینگ در اوایل دههی ۲۰۰۰ با توسعه تکنیکهای جدیدی برای آموزش شبکههای عصبی عمیق مانند شبکههای عصبی کانولوشنالی و شبکههای عصبی بازگشتی آغاز شد.
از دلایل اصلی این بازگشت میتوان به پیشرفت توانایی های محساباتی و میزان دیتای موجود اشاره کرد که به پژوهشگران اجازه میداد به توانند با راحتی بیشتر بر روی مسائل تمرین و تست بکنند.
حال شبکههای عصبی مصنوعی و یادگیری عمیق مرکز بسیاری از زمینهها ازجمله بینایی کامپیوتر، پردازش طبیعی زبان، تشخیص گفتار، رباتیک و غیره به حساب میآیند. آنها فرصتها و کاربردهای جدیدی در حوزه صنایعی از قبیل بهداشت، امور مالی، حمل و نقل و دیگر صنایع ایجاد کردهاند.
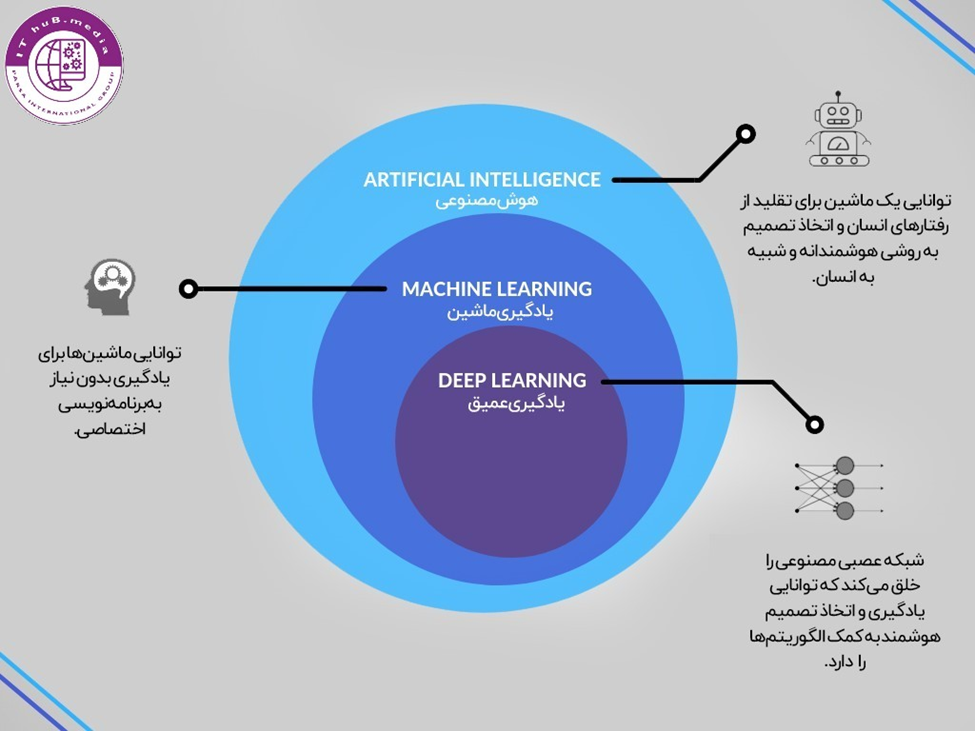
تفاوت یادگیری ماشین و یادگیری عمیق
یادگیری عمیق به عنوان یک زیرشاخه ی یادگیری ماشین برای حل مسائل پیچیده تر و کار با داده های بزرگتر طراحی شده. برای درک بهتر به تصویر زیر توجه کنید.
چالش های یادگیری عمیق
همانطور که قبل تر اشاره شد،الگوریتم های یادگیری عمیق برای حل مسائلی که دارای حجم زیادی از داده هستند طراحی شده اند. این الگوریتم ها بدلیل اینکه از ورودی های خود یاد میگیرند و خود را بهبود میبخشند نیازمند حجم قابل قبولی از داده هستند که در صورت کمبود داده میتوان پروسه ی یادگیری با مشکل مواجه شود.
مشکل دیگر این الگوریتم ها زمان زیادی هست که اغلب نیازدارند. اینگونه الگوریتم ها پروسه ی یادگیری از چند دقیقه تا چندماه بسته به نوع مسئله دارند که در برخی موارد بهبود دادن یا رسیدن به بهترین تنظیمات و خروجی را دچار مشکل میکنند. از مشکلات دیگری که میتوان اشاره کرد نیازمندی به سخت افزاری قوی برای توانایی محاسبه ی حجم بالایی از اطلاعات اشاره کرد.
کاربرد یادگیری عمیق در زندگی واقعی
1- تشخیص تقلب: مدلهای یادگیری عمیق برای تشخیص تقلب در تراکنشهای کارت اعتباری و ادعاهای بیمه در بخش مالی استفاده میشوند.
2-بینایی ماشین:یادگیری عمیق به طور گسترده در مباحثی مانند طبقه بندی و تشخیص اشیا،آنالیز و تشخیص چهره و بسیاری اعمال دیگر در شاخه ی بینایی ماشین استفاده میشود.
3-سلامت و درمان:یادگیری عمیق امروزه کمک های بسیاری در زمینه تشخیص بیماری ها،بهبود دارو ها و آنالیز کردن تصاویر پزشکی انجام داده.
4- خودروهای خودران: مدلهای یادگیری عمیق در خودروهای خودران برای شناسایی و پاسخگویی به شرایط جاده در زمان واقعی استفاده میشوند.
5- بازیهای ویدئویی: صنعت بازیهای ویدئویی با استفاده ازیادگیری عمیق وظایف مختلفی از جمله شناسایی شخصیت، پردازش زبان طبیعی و بهبود اثرات بصری به عهده دارد.
6- رسانههای اجتماعی: پلتفرمهای رسانهای اجتماعی از مدلهای یادگیری عمیق برای ارایه ویژگیهای مختلفی مانند اخبار شخصی سازی شده، شناسایی چهره و تشخیص گفتار استفاده میکنند.
برای ویدئوی آموزشی این مبحث بعلاوه ی مبحث ساخت شبکه ای عصبی ساده میتوانید به آپارات و گیت هاب ما مراجعه بکنید